Independent researchers used controlled ‘sting page’ experiments to establish that ChatGPT is surfacing content derived from Google’s index.
ChatGPT Is Scraping Google—And Here’s the Technical Proof
Abhishek Iyer, a former Google engineer, invented a word. Not a real word—a deliberate nonsense token he describes as “myshkalapatnaik,” a string of characters that had never appeared anywhere on the internet. He placed it, along with a definition, on a webpage with no inbound links. He submitted that page to Google via Search Console and waited for it to be indexed. He told Bing nothing. He told DuckDuckGo nothing. He told Yandex nothing.
Then he asked ChatGPT Plus what “myshkalapatnaik” meant.
ChatGPT returned the definition.
The result, documented and shared publicly, is one of the clearest pieces of technical evidence yet produced that ChatGPT—in its web-enabled modes—is not independently crawling the web to answer your questions. It is, at least in part, reading from Google’s index. The page was created after any plausible training cutoff for the model Iyer queried, it had never been submitted to any other index, and the real-time web search mode was active during the query. There is no training data explanation for the result. There is no independent crawl explanation. The page existed in one place: Google’s index.
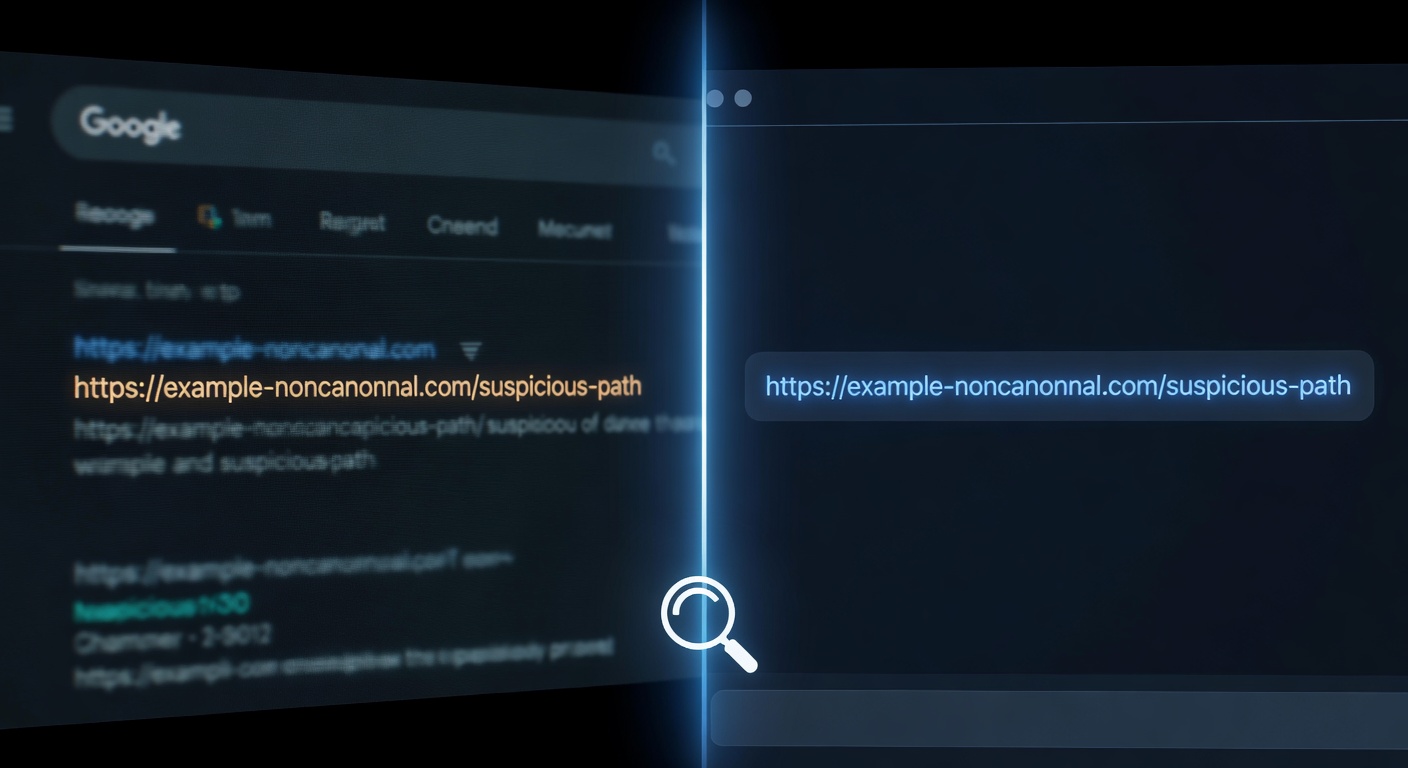
Oh wow… @glenngabe has some new evidence showing ChatGPT is citing non-canonical URLs (after those same URLs appeared in Google search)
Yet another clue that ChatGPT is (still) likely scraping Google to generate answers: https://t.co/cbwHrrNRQs pic.twitter.com/3tN8DrcXYa
— Lily Ray 😏 (@lilyraynyc) February 16, 2026
The Sting Tests
Iyer’s experiment was not a one-off. SEO consultant Aleyda Solís ran a structurally identical test, publishing her methodology and results in full. She created a new page on her site, titled “LLMs.txt Generators,” and immediately queried ChatGPT with web search enabled. ChatGPT told her the URL was “not publicly indexed or possibly outdated.” She then asked Google Gemini the same question. Gemini fetched the live page directly. After Google indexed the page through its normal crawl, Solís returned to ChatGPT. This time, ChatGPT returned an answer—one that matched Google’s SERP snippet verbatim. ChatGPT described its own result as “a cached snippet via web search.”
“So yes, it’s confirmed,” Solís wrote. “ChatGPT is somehow relying on Google Search results snippets for their answers.”
A third independent replication, conducted by ACME.BOT, used two parallel methods: a sting page visible only in Google’s index, and a deep analysis of ChatGPT’s search references. Both pointed to the same conclusion: the paid version of ChatGPT is using Google Search, not Bing, as a primary or fallback retrieval source.
The Commercial Conduit
How, technically, is this happening? Investigative reporting from The Information, summarized by Search Engine Land, points to SerpApi—an Austin, Texas-based third-party service that extracts Google Search results for programmatic consumption. According to The Information‘s reporting, as summarized by Search Engine Land and Tom’s Guide, OpenAI has used SerpApi to obtain Google result data to power ChatGPT’s answers on real-time topics: news, sports, and financial markets, where OpenAI’s in-house index is still catching up. OpenAI has not publicly confirmed a direct partnership with Google, and Google has long attempted to limit automated scraping of its results.
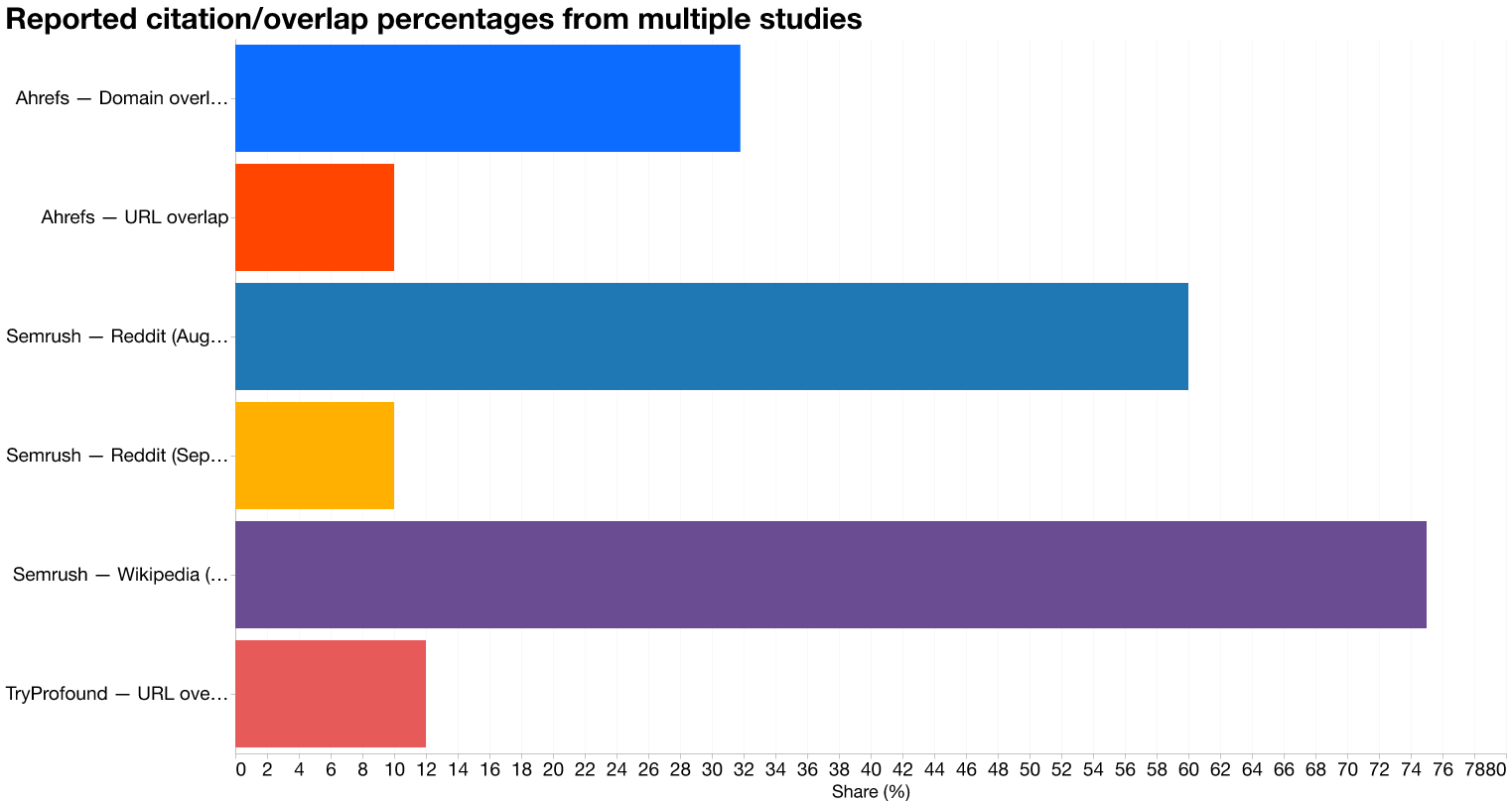
Compiled from Semrush, Ahrefs, and TryProfound reporting
ZDNet’s summary of the reporting notes that OpenAI executives have testified that their goal is to serve the majority of traffic from a first-party index, but acknowledged they are “nowhere near close.” That gap is, apparently, being filled by Google’s data.
The Hybrid Pipeline
The architecture is not a simple pass-through. DevTools logs captured during multiple experiments show ChatGPT making initial Bing requests—but then returning answers that match Google snippets verbatim, even when Bing has no record of the URL in question. Search Engine Journal’s analysis describes this as consistent with a two-step retrieval pipeline: query Bing first, and if coverage is insufficient, fall back to Google-derived data.
Ahrefs’ three-study analysis of 3,311 keywords adds important texture. URL-level overlap between ChatGPT citations and Google’s top-10 SERPs was only 10 percent, but domain-level overlap reached 31.8 percent. ChatGPT frequently cites different pages on the same domains that Google serves—which is consistent with a system that aggregates and reranks results rather than copying Google’s exact page list. The scraping hypothesis and the reranking hypothesis are not mutually exclusive; they describe different layers of the same pipeline.
The strongest systemic evidence linking Google’s backend decisions directly to ChatGPT’s citation behavior at scale comes from a specific API change. Semrush’s 13-week study, tracking 230,000 prompts and more than 100 million AI citations, documented abrupt platform-specific citation shifts that illuminate the architecture’s sensitivity. ChatGPT’s Reddit citations fell from roughly 60 percent of prompt responses in early August 2025 to around 10 percent by mid-September. Wikipedia’s presence in ChatGPT fell from approximately 55 percent to under 20 percent across the same window. Lily Ray noted publicly that this date coincided precisely with Google removing the num=100 parameter from its search API—a backend change that would directly affect any system consuming Google results at scale. A Google configuration decision produced a measurable, near-simultaneous shift in what ChatGPT cited. That is not a coincidence of timing; it is a dependency made visible.
The Canonical Tag Problem
For SEOs, the most operationally significant finding is not the scraping itself. It is what gets scraped—and what that means for URLs a site owner never intended to make canonical.
Google treats rel=canonical as a hint, not a binding directive. On complex sites—those with parameterized URLs, faceted navigation, or standard organic crawl paths—Google can and does elect to index a URL that differs from the one a site owner designated as canonical. That decision has always had ranking implications. It now has AI citation implications too.
The srsltid parameter issue is a specific and acute version of this problem. Lily Ray flagged the pattern with Google Merchant Center’s srsltid parameter URLs—parameterized links appearing in organic SERPs despite canonical tags pointing elsewhere, and then appearing inside ChatGPT Deep Research outputs. Glenn Gabe documented the mechanism in detail: non-canonical URLs surfaced in Google’s search results were ending up in ChatGPT citations. The cascade works like this. A parameterized URL becomes publicly discoverable—through a shared link, a merchant feed, or a crawl path that bypasses a site’s intended architecture. Google indexes it and generates a snippet. A scraper or API consumer reads that snippet. ChatGPT cites the parameterized URL in its answer. The site owner’s canonical tag never had a chance to intervene, because the intervention point was upstream, at the moment of discovery. The remediation path here is specific: block srsltid and similar merchant feed parameters from public discovery at the source, through robots rules and careful auditing of feed pipelines that may be exposing query strings to public crawlers.
The broader canonical-as-hint problem is distinct and requires a different response. When Google elects to index any non-canonical URL—not just merchant feed variants—that URL becomes available to downstream consumers of Google’s index. The wrong page gets cited in AI answers, the wrong URL receives attribution, and the site owner’s intended canonical receives neither the ranking signal nor the AI visibility. Google Search Console coverage reports, historically used to identify indexing errors, should now be read as AI citation risk signals: any URL Google has indexed against a site owner’s canonical preference is a URL that may appear in a ChatGPT answer.
The Quantified Dependency
Stan Ventures’ study, analyzing 11 website subfolders that experienced severe organic traffic declines between January 20 and February 16, 2026, put numbers on what practitioners had been observing qualitatively. Every subfolder that lost Google organic visibility also lost AI search citations. The average organic traffic decline was 26.7 percent. The average AI citation decline was 22.5 percent. ChatGPT’s average citation decline for those same subfolders was 27.8 percent.
This correlation is observational, and correlation alone does not prove the scraping mechanism. But it is precisely what the scraping hypothesis predicts: if ChatGPT is reading from Google’s index, then Google’s ranking decisions are upstream of ChatGPT’s citation decisions. The data is consistent with that structure. Lose Google visibility, lose AI visibility. The two are not separate channels with separate optimization levers. They are, at least in significant part, the same channel.
What This Means for Technical SEO
The practical reframe is significant. Canonical hygiene, parameter blocking, and indexing control have always mattered for ranking. They now also determine which URLs get cited inside AI-generated answers delivered to users who may never see a traditional search results page.
The defensive priorities follow directly from the evidence. Parameterized URL variants should be blocked from discovery at the source. Merchant and feed pipelines that may be exposing srsltid or similar query strings to public crawlers warrant immediate auditing. Google Search Console coverage reports should be reviewed not just for duplicate content risk but for AI citation exposure. Any URL Google has elected to index against a site owner’s canonical preference is a URL that may appear in an AI answer—and correcting that requires intervening before Google indexes it, not after.
TechCrunch’s reporting on ChatGPT share URLs being indexed by Google—until OpenAI ended the experiment—illustrates the same principle from the other direction. Discovery is the root step. Once a URL is publicly discoverable and Google indexes it, it is available to any downstream consumer of Google’s index, including the systems that power the AI answers now displacing traditional search traffic.
OpenAI has not provided an engineering disclosure of its exact retrieval architecture for each product mode. The strongest claims in this body of evidence rest on converging external tests, log captures, and vendor reporting rather than an internal audit. But the convergence is substantial: multiple independent researchers, using different methodologies, in different countries, across different time periods, have produced results pointing to the same conclusion.
Iyer’s nonsense word was the cleanest test. A term that existed nowhere on the internet, placed on an unlinked page, submitted only to Google, created after any plausible training cutoff, returned by ChatGPT with its definition intact. The training data hypothesis fails on the timeline. The independent crawl hypothesis fails on the submission record. One explanation fits all three constraints.
ChatGPT read it from Google.