Google’s March Spam 2026 core update produced volatility 3.2x higher than the December 2025 baseline, reshuffling entire content verticals within days.
Google’s March 2026 Spam / Core Update: Winners, Losers, and What Changed
Update: The March CORE update is just rolling out, this article covers the March Spam update which was previously interpreted as a March Core update by the community.
Today we released the March 2026 core update. We’ll update our ranking release history page when the rollout is complete: https://t.co/tBENzbTqB2
— Google Search Central (@googlesearchc) March 27, 2026
On March 18, an affiliate site owner posted in the SEO community at large that his traffic had dropped 61% in five days. His site published 70 AI-generated product roundups per week. No named author. No original research. By the time he posted, the pattern was already clear to anyone watching the rank trackers: Google’s March 2026 core update was not hitting sites at random. It was hitting a specific production model.
Search Liaison Danny Sullivan confirmed the rollout on March 16. But rank trackers had been lighting up since March 3. Semrush Sensor peaked at 9.4 out of 10 on days three through five — 3.2 times the volatility recorded during the December 2025 update baseline. By the end of the first two weeks, more than 55% of monitored sites had recorded ranking changes, according to tracking data compiled by Kahunam. Thin affiliate pages reported traffic losses between 40% and 70%. Sites publishing more than 50 AI-generated articles per month averaged traffic declines of approximately 73%, per SerpNap’s post-update analysis of monitored domains.
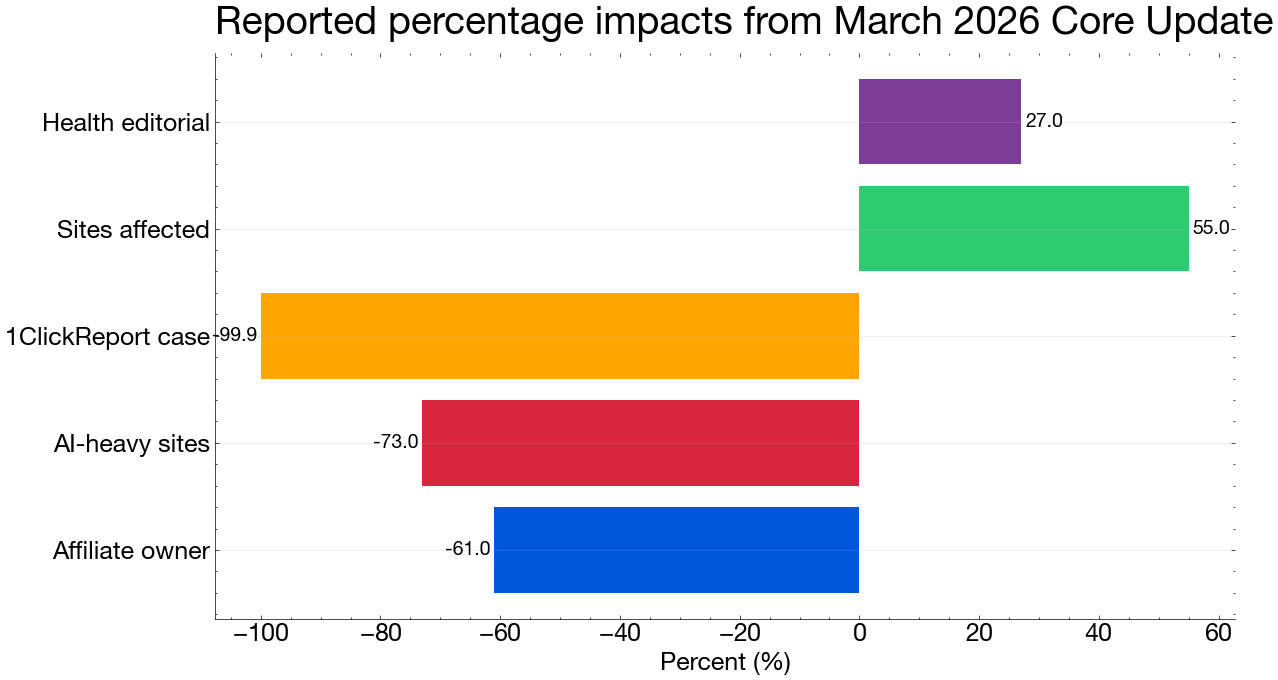
Reporting and post-update analyses from Kahunam, SerpNap, and 1ClickReport; article reporting of individual site outcomes
Sites that looked different — smaller editorial teams publishing original research, proprietary data, and named authors — held. One content vertical documented in community reporting: a three-person health editorial team publishing eight original, expert-reviewed pieces per month saw a 27% traffic gain in the same window. Clean internal linking. Identifiable bylines. No scaled AI output. That is the winners column.
A Compounding Algorithmic Event
The March 2026 core update did not arrive alone. It followed a February Discover-only core update — the first of its kind Google had ever deployed — which had already reshuffled Discover-driven traffic for publishers dependent on that channel. Then the March core update rolled out while a concurrent March Spam Update was still in motion. Two significant algorithm changes in a single month is unusual even by Google’s accelerating standards. Isolating cause — spam filter, core update, or Discover-specific signal — required more methodological rigor than most teams were prepared for mid-rollout.
Google’s own framing pointed squarely at scaled AI content abuse and low-quality automatically generated output as the primary enforcement targets. Critically, the mechanism is not a blanket penalty on AI-assisted writing. It targets what Google’s documentation describes as “content velocity” — the ratio of publication rate to demonstrable editorial capacity. A team of three editors publishing 200 articles a week produces a signal. That signal is now consequential.
One additional finding worth stating plainly: Google completed the rollout of its branded-query filter inside Search Console on March 11 — five days before Sullivan’s formal update announcement. For the first time, SEOs could isolate genuine organic losses from brand-search noise inside GSC itself. Google appeared to have finalized a key diagnostic tool before the enforcement event went live.
What the Data Actually Shows
Three instrumented signal classes separated real losses from measurement noise fastest.
The first is rank-tracker volatility at the vertical level. Tools including AccuRanker, Semrush, and SISTRIX recorded category-level reshuffling — not just individual keyword fluctuations — with entire affiliate and automated-content verticals displaced within 72 hours. Sites with original research as their primary content asset showed the strongest stabilization signals in the same trackers.
The second signal class is AI Overview citation presence. Tools including Semrush, Ahrefs, SISTRIX, and PromptRush now track whether a domain appears inside Google’s AI Overview answers for target queries. In multiple post-update cases, practitioners documented traffic collapse on queries where blue-link positions had not meaningfully changed. The explanation: Google’s AI answers were resolving queries before users reached any listed site. A site can hold position three and lose 40% of its clicks if it drops out of the AI Overview sitting above it. This distinction determines whether the recovery path involves content quality or structured data and citation-earning — two very different remediation timelines.
The third signal is Search Console’s non-branded query performance, made substantially more analyzable by the March 11 branded-query filter. Sites reporting dramatic traffic drops that turned out to be entirely concentrated in branded queries — often the result of reduced branded search volume, not algorithmic demotion — were misattributing cause without this filter. Cross-validate with independent rank trackers. Google confirmed a brief serving anomaly during the rollout window, and GSC was documented as missing page indexing data during portions of the period. Server logs are not optional here.
The E-E-A-T Signal Running in Parallel
Alongside the anti-AI-spam enforcement, a second pattern is visible in the post-update data. The share of top-ranking pages in health, finance, and legal verticals displaying detailed author credentials rose from roughly 58% to 72% following the update, according to Kahunam’s post-update content analysis. Google appears to be evaluating not just what content says but who is accountable for it — and whether the production architecture behind a site is consistent with genuine editorial capacity. Sites that used AI to write substantive YMYL content but stripped out authorship signals, or relied on generic bios with no demonstrable subject-matter expertise, absorbed losses on both enforcement vectors simultaneously.
Who Is Recovering — and What Comes Next
Sites showing the clearest recovery trajectories share three characteristics: original research or proprietary data as the primary content asset, clean internal linking architecture, and identifiable human editorial accountability at the byline and site level. These are structural content decisions that predate any single update. Google’s own recovery guidance frames the path back as a content audit process measured in months, not a metadata patch measured in days.
For sites built on templated or unedited AI output at scale, a 73% average traffic decline is not a penalty to appeal. It is a signal that the underlying production model has been devalued, and that recovery requires demonstrating — over an extended crawl and indexing cycle — that content now being produced reflects genuine expertise and editorial investment.
The sequential update cadence in early 2026 has now produced three major core updates in roughly three months. A further refinement update before mid-year is plausible. The signal to watch: whether sites that have already rebuilt content architecture around named authorship and original research begin showing measurable recovery in the May crawl cycle. If they do, the enforcement model is working as designed and the next update will tighten it further. If recovery remains flat even for structurally sound sites, a recalibration becomes more likely. Either way, the enforcement direction is set.